VisQ (Visual Query)
VisQ (Visual Query)
iOS application for composed image and video retrieval on iPhone
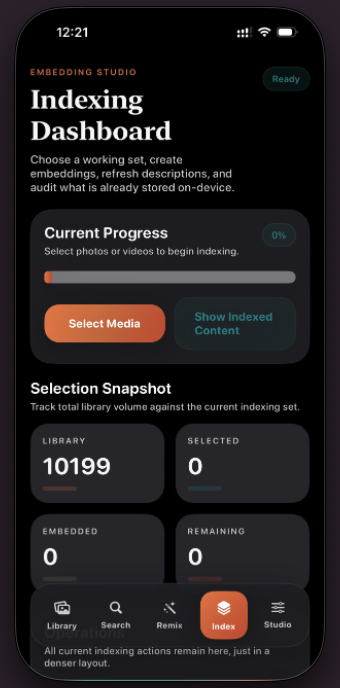
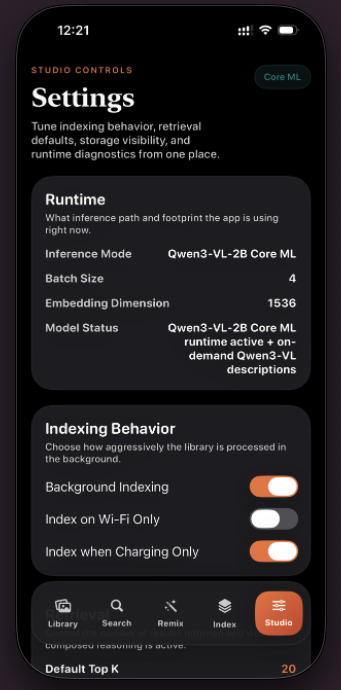
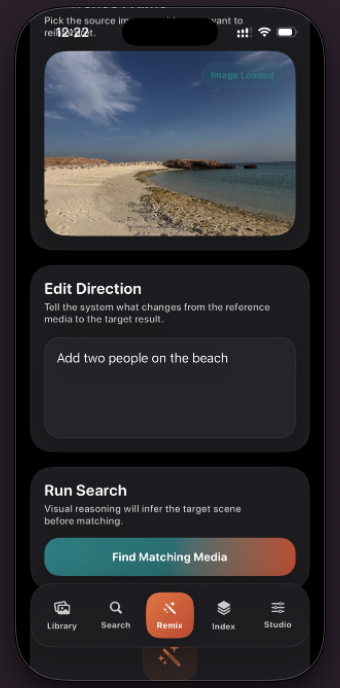
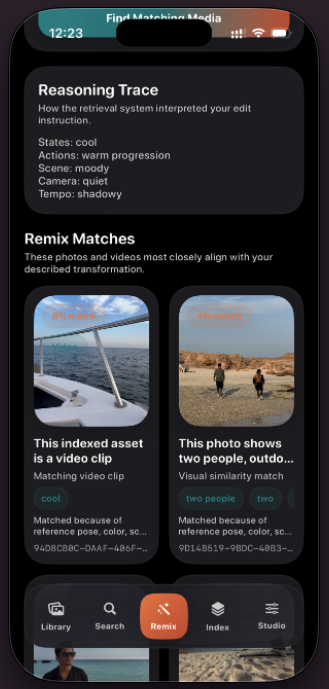
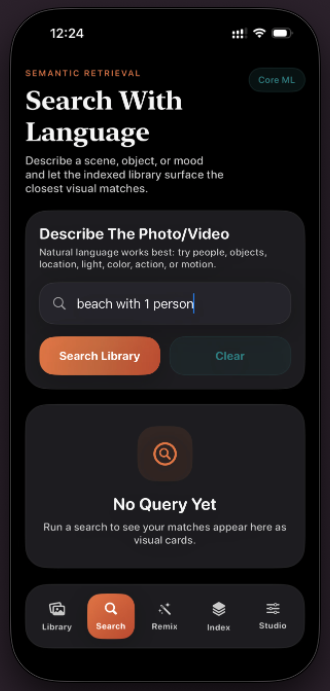
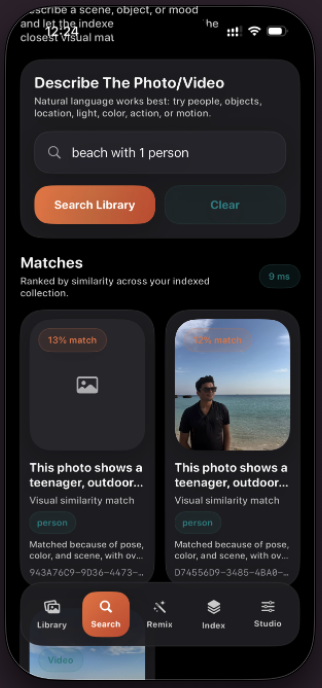
VisQ brings reason-aware visual retrieval to iPhone with an on-device Qwen3-VL-2B Core ML runtime. Users can search personal media with natural language or run composed retrieval using a reference image + edit prompt, then inspect "Why This Matched" explanations powered by the model's reasoning capability.
On-device AI
Composed Retrieval
Explainable Results
Privacy-First
Offline-First
- Indexes local photos and videos directly from the iPhone photo library.
- Supports text search and reference-image-guided retrieval with scene edits.
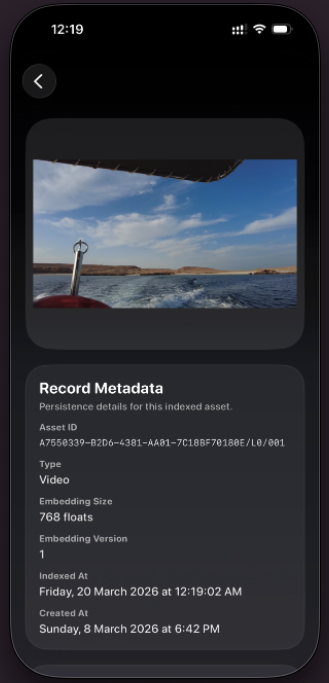
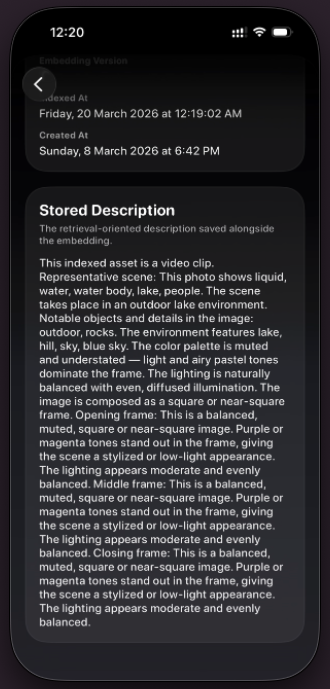
- Surfaces human-readable match reasons and visual explanation chips.
- Keeps embeddings, ranking, and inference on-device for privacy-preserving search.
Built from research
VisQ is based on our recent research work CoVR-R: Reason-Aware Composed Video Retrieval, translating reason-aware composed retrieval into a practical iPhone app for local-first multimodal search.
Available now on the Apple App Store.